Categories
0
Featured Themes


Directory, E-Commerce, Featured, WordPress  60%40%BeProThemes.com showcases the ByCater Product Catalog theme. This theme is great for any type of product listings website. In fact, we use this theme to power B...$9.99
60%40%BeProThemes.com showcases the ByCater Product Catalog theme. This theme is great for any type of product listings website. In fact, we use this theme to power B...$9.99
 60%
60% 40%
40%4
3
Search Results
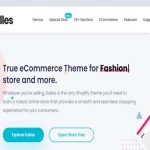
E-Commerce, Miscellaneous, Shopify 0%0%With over 11,000 sales, this premium Shopify theme is popular. Kalles is focused on the fashion industry and offers multiple customizations to showcase your inv...$89.00
0%0%
E-Commerce, Shopify, Starter 0%0%This is a free Shopify starter theme. As with all Shopify-created themes, this website design theme provides a range of basic features. We think that it's ideal...Free
0%0%
E-Commerce, Shopify, Starter 0%100%Dawn is one of the default themes available on Shopify. Our BePro Software team reviewed this theme and found it to be an easy entry into Shopify features. Take...Free
0%100%
E-Commerce, Miscellaneous, Portfolio, Starter, WordPress 0%0%Home services is a feature-rich WordPress theme for local businesses like: construction, HVAC, repair and handyman, maintenance and renovation, plumbers and plu...$49.99
0%0%
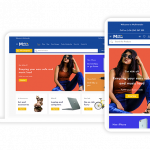
E-Commerce, WordPress 0%0%Th Shop mania is a page builder based eCommerce WordPress theme for shopping websites. . It is a very lightweight and cleanly-coded fast theme, Search Engines w...Free
0%0%
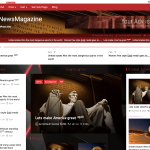
Miscellaneous 100%0%Color NewsMagazine is a free WordPress theme. It is designed to build a magazine and newspaper website. Its blog design is also suitable for a professional blog...Free
100%0%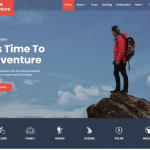
E-Commerce, Miscellaneous, Starter, WordPress 0%0%Adventure is a responsive sport WordPress theme has been designed and created to cater to the needs of those who create adventure sports websites and adventure ...$39.00
0%0%
2
1
4
4
36
Sponsors

Sponsors
